

DFS - 깊이 우선 탐색
말 그대로 노드에 연결된 최하층 노드까지 탐색하고 다시 분기점에서 가지 않은 노드가 있다면 이동하는 방식으로 진행되는 탐색이다. DFS에는 스택과 재귀를 이용한 구현으로 나뉘게 되고, 방식에 따라 탐색순서가 달라질 수 있다.
1. 스택을 이용하는 경우

스택은 특성상 한 방향으로 입출력이 된다. 위 그림의 예시로 출력되는 순서와 방식을 알아보자.
1. 먼저 root인 A노드에서 시작한다.
2. A 노드가 출력되면, 이하 자식 노드인 B, C, D가 들어간다.
3. 위에서 출력되니까 D 노드가 출력되고 자식 노드인 H가 입력된다.
4. 맨 위에 있는 H 노드가 출력되고, 자식 노드는 없으므로 그 뒤에 있는 C 노드가 출력된다.
5. C 노드의 자식노드인 G 노드가 들어간다.
6. G 노드가 출력되고, 자식노드가 없으므로 아래 있던 B 노드가 출력된다.
7. B 노드의 자식노드인 E, F가 순서대로 들어가고 위에서부터 출력되므로 F, E 순으로 출력된다.
결과적으로 A - D - H - C - G - B - F - E 순으로 출력되는 것을 알 수 있다.
2. 재귀를 이용하는 경우
재귀를 이용하는 경우에는 DFS 메서드가 반복되서 실행되는 것으로 먼저 찾은 노드에서 가장 아래 깊이에 있는 노드까지 출력되고 다음 자식노드의 또 최하위 노드까지 실행되는 것을 반복한다.
즉, 위에 같은 트리 예시에서 출력순서는 A - B - E - F - C - G - D - H 순이다.
BFS - 너비 우선 탐색
너비 우선 탐색은 root 노드 이하의 자식노드를 다 확인하고 다음 층의 노드를 확인하는 방식으로 탐색이 일어난다. BFS의 구현은 큐를 이용한다.

DFS를 설명한 같은 트리 구조로 BFS 탐색 순서를 표현해봤다. 큐 구조는 특성상 한 쪽 방향으로 입력, 다른 방향으로 출력이 가능한데, 위 이미지에서는 위로 입력, 아래로 출력이 되는 것으로 보면 된다.
1. 먼저 root 노드인 A가 들어간다.
2. A 노드를 출력하면 자식노드 B, C, D가 들어간다.
3. 맨 아래에 있는 B 노드를 출력하면, B의 자식 노드인 E, F가 순서대로 위에 쌓인다.
4. C 노드를 출력하면, 자식노드 G는 맨 위에 쌓인다.
5. 다음 D 노드를 출력하면, 자식노드 H가 맨 위에 쌓인다.
6. 이하 순서대로 자식노드들이 출력된다.
결과적으로, A - B - C - D - E - F - G - H 순으로 출력됨을 알 수 있다.
한 눈에 보이는 탐색 방식 비교
아래는 위 각각의 방식에서 사용된 트리탐색 순서를 한 눈에 볼 수 있도록 정리한 이미지이다. DFS 스택구현시와 DFS 재귀 구현시, BFS 큐 구현시 출력되는 노드 순서를 표기했다. 상황에 따라 순서는 변동될 수 있으며, DFS 스택과 BFS 큐 구현의 순서도 양이 적다고 해서 모든 경우에서 빠르게 출력되는 방법이 아님에 유의해야 한다.

DFS, BFS 구현 전에 알아두어야 할 상식
백준에서는 노드, 간선 수, 탐색 시작 위치를 먼저 알려주고 노드와 간선이 연결된 종류를 system.in으로 BufferedReader 처리해서 읽어들이는 방식으로 출제되는 것을 볼 수 있다. 그리고 프로그래머스 문제들은 주로 노드와 간선이 연결된 종류가 배열로 주어진다.
| 백준 | 프로그래머스 |
 |
 |
즉, 구현을 위해 우리가 알아야하는 것은 어떤 노드들이 있는지, 간선의 수 또는 간선이 어떻게 노드와 이어져 있는지와 탐색을 시작하는 위치이다.
여기서 노드와 간선이 어떻게 연결되어 있는지 데이터로 가지고 가는 방식은 인접행렬 방식과 인접 리스트 방식이 있다. 이 부분을 먼저 알아두면 각 탐색방식에 따른 구현을 이해하기 더 수월하기 때문에 먼저 정리해보았다.
(위에 예시로 들은 트리 구조로 양방향 방식으로 정리했다.)
인접 행렬방식
먼저, 인접 행렬방식은 각 노드를 기준으로 서로 연결된 경우의 모든 배열에 1의 값을 추가하는 방식으로 연결여부를 표현한다. 아래 표에서도 볼 수 있듯이 대각선을 중심으로 값이 겹치는 것을 볼 수 있다.
| A | B | C | D | E | F | G | H | |
| A | 1 | 1 | 1 | |||||
| B | 1 | 1 | 1 | |||||
| C | 1 | 1 | 1 | |||||
| D | 1 | 1 | 1 | |||||
| E | 1 | |||||||
| F | 1 | |||||||
| G | 1 | |||||||
| H | 1 |
위 인접 행렬 방식을 간단하게 코드로 나타내보면 다음과 같다. 연결노드 지점을 배열에서 각 노드의 위치에 맞게 표시해주는 것이다.
// n은 노드의 수
int[][] arr = new int[n+1][n+1];
arr[0][1] = arr[1][0] = 1
인접 리스트 방식
다음 인접 리스트 방식은 위 인접 행렬 방식과 다르게 불필요한 메모리 소모를 없애고 딱 연결된 데이터만을 저장해놓는 방식으로 메모리 공간을 적게 사용한다는 장점이 있지만, 각각의 노드 연결을 확인하려면 끝까지 확인을 해봐야 한다는 점에 상황에 따라 성능이 더 낮을 수 있다.
| A | B | C | D |
| B | A | E | F |
| C | A | D | G |
| D | A | C | H |
| E | B | ||
| F | B | ||
| G | C | ||
| H | D |
인접 리스트 방식의 데이터 구조를 코드로 나타내보면 다음과 같다. 간략하게 작성한 코드로 이런 식으로 담기는구나 느낌만 가져가면 될 것 같다.
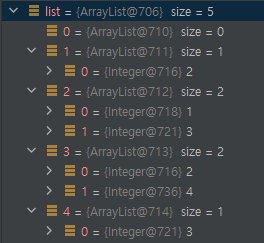
int n = 4; // 노드의 수
int[][] node = {{1,2},{2,3},{3,4}};
ArrayList<ArrayList<Integer>> list = new ArrayList<>();
for(int i=0; i<n+1; i++){
list.add(new ArrayList<>()); // 초기화
}
for(int i=0; i<node.length; i++){
list.get(node[i][0]).add(node[i][1]);
list.get(node[i][1]).add(node[i][0]);
}
Java로 구현하는 DFS, BFS
그럼 이제 진짜로 Java로 DFS, BFS 방식을 구현해보자. (백준 1260번 참조)
먼저 백준 문제를 기준으로 DFS, BFS를 구현하는 방식을 작성했는데 각각의 탐색방식을 메서드로 만들기 때문에 공통으로 사용될 변수들을 private static 변수처리해서 main 함수 밖으로 처리했다.
main 함수에서는 문제의 값을 읽어들여야 하기 때문에 system.in 처리 후 BufferReader와 StringTokenizer로 나눠서 변수처리 및 인접 행렬 처리해주었다. Scanner 보다 BufferReader를 사용한 처리가 속도가 더 빠르기 때문에 BufferReader를 추천한다.
(프로그래머스 문제에서는 대부분 따로 변수로 주어지는 경우가 많아서 각각 나눠서 읽어드릴 일이 없었다.)
그리고 인접 행렬 처리할 int[][] arr과 방문처리된 노드를 표시하기 위한 boolean[] visited가 필요하다.
private static StringBuilder sb = new StringBuilder();
private static boolean[] visited;
private static int[][] arr;
private static int n, m, v;
private static Queue<Integer> queue = new LinkedList<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken()); // 노드 수
m = Integer.parseInt(st.nextToken()); // 간선 수
v = Integer.parseInt(st.nextToken()); // 시작 노드
visited = new boolean[n+1]; // 방문여부 체크
arr = new int[n+1][n+1]; // dfs
for(int i=0; i<m; i++){
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
arr[a][b] = arr[b][a] = 1;
}
dfs(v);
sb.append("\n");
bfs(v);
System.out.println(sb);
}
DFS
DFS 재귀방식을 이용한 코드다. for문 이하로 DFS 메서드인 dfs(i); 를 조건에 해당하는 경우 계속적으로 호출하므로써 깊이 우선 탐색으로 시작 노드에서 최하층 노드가 없을 때까지 탐색이 가능하게 한다. 아래 코드에서 인접 행렬 방식을 사용하기 때문에 arr[][]에 값이 1인 경우, 즉, 간선으로 연결된 경우에만 탐색이 가능하도록 하고 있는 것을 알 수 있다.
public static void dfs(int start) {
visited[start] = true;
sb.append(start+" ");
for(int i=1; i<=n; i++){
if(!visited[start] && arr[start][i]==1){
dfs(i);
}
}
}
BFS
큐를 이용하기 때문에 큐 queue의 값이 없을 때까지 출력해서 visited 노드 처리를 해주는 것을 알 수 있다. BFS 탐색에서는 while을 통한 반복처리를 해주고 있다.
public static void bfs(int start) {
queue.add(start);
visited[start] = true;
while(!queue.isEmpty()) {
start = queue.poll();
sb.append(start + " ");
for(int i = 1 ; i <= node ; i++) {
if(!visited[i] && arr[start][i]==1) {
queue.add(i);
visited[i] = true;
}
}
}
}
'알고리즘과 코테' 카테고리의 다른 글
| [Java | 백준 1436번] 영화감독 숌 (0) | 2021.04.08 |
|---|---|
| [Java | 백준 1427번] 숫자의 개수 (0) | 2021.04.07 |
| [Java | 백준 11650번] 좌표 정렬하기 (0) | 2021.04.07 |
| [Java | 백준 5585번] 거스름돈 (0) | 2021.03.29 |
| [Java | 백준 13277번] 큰 수 곱셈 (0) | 2021.03.29 |
- putty
- SQLD
- 오늘의코딩
- 노개북
- gradle
- 정보처리기사 필기
- 정보처리기사 실기
- 독서후기
- 개발도서
- git연동
- LifecycleException
- JIRA
- EC2
- java
- jdbc
- 실용주의프로그래머
- IT 5분 잡학사전
- 북클럽
- gradle build
- ubuntu
- 기술블로그
- 정보처리기사
- AWS
- intellij
- 웹페이지만들기
- 배포
- filezila
- spring
- 노마드코더
- 호스팅영역
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |